
In recent months, I’ve encountered numerous articles with titles such as “20 Linux Commands You Should Know” or “Linux Survival Guide.”
however, most of these articles cover basic commands like ls or echo.
Considering that my audiences are already familiar with these foundational commands, this article takes a different approach.
This collection includes commands that are more advanced and can help you become better at managing a Linux system.


Table of Contents
ss — display detailed information about socket connections
The “ss” command in Linux is a utility used to display detailed information about socket connections, network interfaces, and network statistics. It stands for “Socket Statistics” and provides a powerful alternative to the older “netstat” command.

The “ss” command can display various information related to network connections.
The “ss” command offers numerous options and filters that allow you to customize the output and narrow down the displayed information.
ss -ntaupe
See also: Mastering the Linux Command Line — Your Complete Free Training Guide
- n lists processes using numeric addresses (eg, IP addresses instead of DNS names)
- t lists TCP connections
- a lists all connections — listening and established
- u lists UDP connections
- p shows the process using the socket — probably the most useful
- e shows some extended information, like the uid.
Here are the options I usually use.
ss -peanut
This command will display all (a) TCP (t)/UDP (u) connections, along with the associated process information (p) and extended(e) information.
The output can be quite extensive. By filtering the output with grep, you can narrow down the results and focus on specific information that meets your requirements.
For example, if you want to find all established TCP connections, you can use the following command:
ss -peanut|grep ESTAB
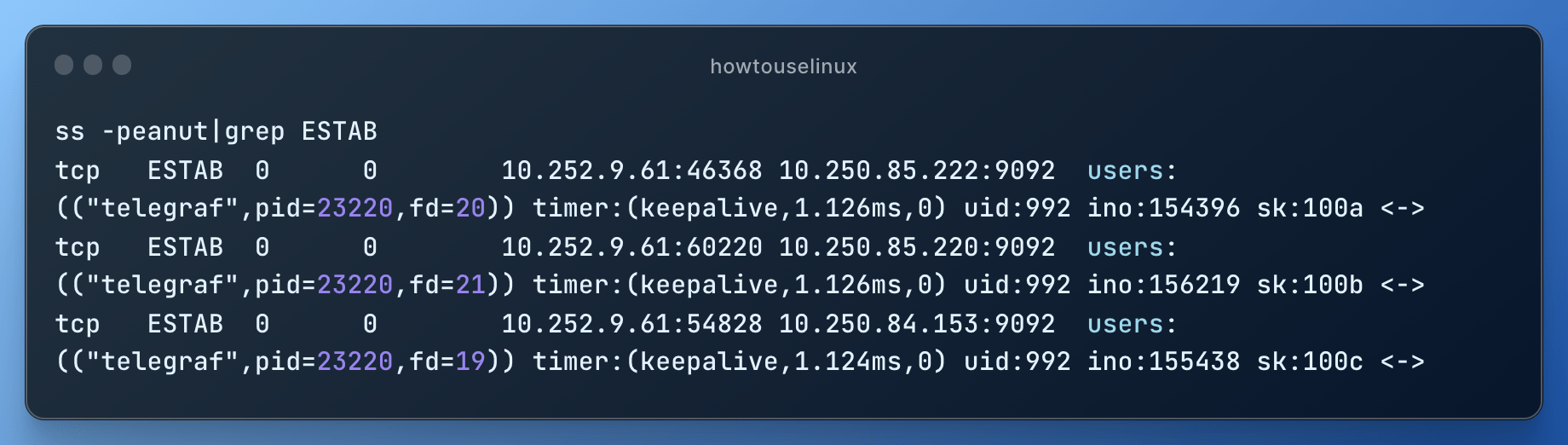
This command will show only the lines containing the keyword “ESTAB,” indicating established TCP connections.
If you need to find out the port number associated with a specific process, you can use the following command.
Replace <process_id> with the actual process ID of the target process.
ss -peanut | grep <process_id>
A shorter combination of flags for this purpose is “-ntpl”. This command will only list the listening tcp connection.
sudo root@howtouselinux: ss -ntpl
State Recv-Q Send-Q Local Address:Port Peer Address:PortProcess
LISTEN 0 64 0.0.0.0:46465 0.0.0.0:*
LISTEN 0 64 0.0.0.0:2049 0.0.0.0:*
LISTEN 0 4096 0.0.0.0:58947 0.0.0.0:* users:(("rpc.statd",pid=2811,fd=10))
LISTEN 0 5 0.0.0.0:35587 0.0.0.0:* users:(("ecbd",pid=2767,fd=5))
LISTEN 0 50 0.0.0.0:139 0.0.0.0:* users:(("smbd",pid=2770,fd=54))
Shell Job control in Linux shell
Job control in the Linux shell refers to the ability to manage and control multiple running processes, also known as jobs. It allows you to start, stop, pause, resume, and manage the execution of multiple processes simultaneously.
During my work, I frequently switch between a text editor and log files.
When using tools like vim or less to read log files, I often utilize Ctrl+Z to send the current application to the background, allowing me to focus on something else.
In case I need to recall what processes are currently running, the “jobs” command provides a list of active jobs.
To bring a backgrounded application back to the foreground, I simply use “fg <jobnumber>”.
These capabilities save me the hassle of opening multiple SSH connections and enhance my productivity.
Here are some commonly used shell job control commands:
- &: Placing an ampersand (&) at the end of a command allows it to run in the background. This means the command will execute independently, and you can continue using the shell without waiting for it to finish.
- Ctrl + Z: Pressing Ctrl + Z suspends a foreground process and puts it into a stopped state. The process is paused and removed from the foreground, allowing you to use the shell while it is paused.
- jobs: The jobs command lists all the currently running jobs in the shell. It displays the job ID, state, and command associated with each job.
- bg: The bg command resumes a stopped or suspended job in the background. You can use it to restart a stopped job and allow it to continue executing in the background.
- fg: The fg command brings a background job to the foreground. It resumes a stopped or suspended job and allows you to interact with it directly in the foreground.
- kill: The kill command is used to terminate a running process or job. You can specify the process ID (PID) or job ID to kill a specific process.
- Ctrl + C: Pressing Ctrl + C sends an interrupt signal (SIGINT) to the currently running foreground process, causing it to terminate.
openssl command in Linux – SSL certificate tool
When it comes to investigating x509 certificates, “openssl” is a valuable tool.
By using commands like “openssl x509 -in foo.cert -text -noout”, you can extract detailed information from certificates.
This is particularly useful for checking certificate expiration dates and conducting similar analyses.
OpenSSL allows you to verify if a certificate is currently valid by checking its expiration date and against a Certificate Authority (CA) chain.
openssl verify certificate.pem
You can use OpenSSL to verify the entire certificate chain by providing both the certificate and the CA bundle.
openssl verify -CAfile ca-bundle.pem certificate.pem
OpenSSL can be used to test SSL/TLS connections to a server and inspect the server’s certificate.
openssl s_client -connect example.com:443
strace command in Linux – tracing system calls made by processes
“strace” is a powerful utility for tracing system calls made by processes, such as fopen or flock. It provides insights into the specific system-level operations being executed.
“strace” works by attaching to a running process or launching a new one, and then intercepting and logging the system calls that the process makes to the kernel.
These system calls include operations such as file I/O (e.g., open, read, write, close), process management (e.g., fork, execve, exit), and more.
To use “strace,” you typically run it followed by the command you want to trace. For example:
strace -o output.txt ls -l /tmp
In this example, “strace” traces the ls -l /tmp command and logs the output to a file called “output.txt.” You can then analyze the “output.txt” file to see the system calls made by the “ls” command.
“strace” offers a wide range of options for customization. You can filter the types of system calls to trace, follow child processes, and even attach to already running processes. The options allow you to tailor the tracing to your specific needs.
dd command in Linux – copy data
The “dd” command is a handy tool for direct writing and copying of data to storage devices.
Interestingly, “dd” stands for “converting and copying” files, but it couldn’t be named “cc” due to the already existing C compiler. Check more about how to use dd command to test storage performance
Here’s the basic usage of the dd command:
dd if=input_file of=output_file [options]
if: This specifies the input file or device from which dd reads data.
of: This specifies the output file or device to which dd writes data.
You can use dd to create an empty file of a specific size like this:
dd if=/dev/zero of=newfile bs=1M count=10
This command creates a new file called newfile filled with zeros, and it’s 10 MB in size (bs stands for block size, and count specifies the number of blocks).
Important Notes:
- Be extremely cautious when using the dd command, especially with block devices. Using it incorrectly can lead to data loss.
- Double-check the source and destination paths to avoid overwriting important data.
dig command in Linux – interact with DNS
To handle multiple domains and interact with DNS effectively, I rely on “dig”. This simple yet powerful tool allows me to quickly run DNS queries and retrieve valuable information about domain names. Learn more about how to use dig command

To query for the IPv4 address (A record) of a domain, simply provide the domain name as an argument:
dig example.com
This command will return the IPv4 address associated with “example.com.”
To Reverse DNS lookup (PTR record):
dig -x 8.8.8.8
This command performs a reverse DNS lookup for the IP address “8.8.8.8” and retrieves the associated PTR (Pointer) record.
Querying a specific DNS server:
dig example.com @ns1.exampledns.com
This command queries the DNS server “ns1.exampledns.com” for the DNS records of “example.com”. It allows you to specify a specific DNS server to retrieve DNS information.
These are just a few examples of the “dig” command usage. It offers many more options and functionalities, such as setting the DNS query type and controlling the output format. The “dig” command is a valuable tool for DNS troubleshooting, analyzing DNS configurations, and gathering DNS-related information.



recently I use nc command to test the network connectivity for remote server. It is very powerful.
I am still using netstat command. It is handy than ss command.
Thanks for the article.
I am managing 20 DNS servers. Dig command is my favorite. I use it everyday.
Thanks for sharing the shell short cut. ctrl +Z . I would definitely try it.
You should add more commands to the list like iostat, iotop etc.
cool. Great article. I learn a lot. By the way, I am a Linux beginner.
Tcpdump should be on the list. I find it very useful when dealing with network issues.
openssl is much more powerful than you mentioned in the article.
great
Write more articles like this.
netstst -anpl is my favorite. I use it everyday.
i never use dd command to copy date. Cp and scp are the my favorites for copying files.
I am a storage engineer. I need to scan storage, expand disk and manage lvm task etc. If you can add more commands like this, it would be great.
Great. It is very helpful.
Thanks for the detailed explanation. how can I use dig command to query the DNS record from one specific DNS server?